
04-1 통계로 요약하기
<추가숙제>
- 평균 : 데이터 값을 모두 더해 데이터 값의 개수로 나눈 것, 평균을 구하는 방법은 정말 다양하며 상황에 맞게 적절한 평균을 도출 할 수 있어야함
- 중앙값 : 데이터가 홀수인 경우에는 중간에 위치하는 값, 짝수인 경우에는 가운데 두 값의 평균, 즉 데이터의 50%에 해당하는 부분
- 최솟값 : 말 그대로 시리즈 내에서 가장 작은 값을 나타냄
- 최댓값 : 최솟값과 마찬가지로 시리즈 내에서 가장 큰 값을 나타냄
- 분위수 : 순서대로 정렬한 데이터를 일정한 간격으로 나누는 기준점에 해당하는 것을 나타냄
- 분산 : 평균으로부터 데이터가 얼마나 퍼져있는지를 나타내는 지표. 분산이 클수록 데이터가 넓게 펴져있음. 각 데이터에서 평균을 빼고 제곱한 값을 더해 데이터의 개수로 나눈 값
- 표준편차 : 분산에 제곱근을 해준 값
- 최빈값 : 시리즈 내에서 가장 자주 나온 값을 나타냄
| 기술 통계량 | 메서드 | 기타 |
| 요약통계 | DataFrame.describe() | - 수치형 열에 대한 요약통계를 보여줌 - include 매개변수를 통해 다른 데이터 타입의 열의 기술통계 가능 |
| 평균 | Series.mean() np.mean(Series) np.average(Series, weight =) |
- average()를 사용하는 경우 weight 매개변수를 사용해 가중 평균을 구할 수 있음 - 가중평균이란 평균을 구할 때 각 값의 중요도에 따라 가중치를 부여하여 계산하는 평균값 |
| 중앙값 | Series.median() np.median(Series) |
|
| 최솟값 | Series.min() np.min(Series) |
|
| 최댓값 | Series.max np.max(Series) |
|
| 분위수 | Series.quantile() np.quantile(Series) |
- quantile(0.25) : 하위 25%에 해당하는 값 출력 |
| 분산 | Series.var() np.var() |
- 판다스에서는 ddof의 디폴트 값이 1로 분산을 계산 할 때 분모를 n-1로 계산한다. - 넘파이에서는 ddof의 디폴트 값이 0으로 분산을 계산 할 때 분모를 n으로 계산한다 - ddof를 조절하여 자유도를 조정할 수 있다 |
| 표준편차 | Series.std() np.std() |
- 분산과 마찬가지로 ddof 매개변수 조절가능 |
| 최빈값 | Series.mode() | - 문자형, 수치형 모두 사용 가능 |
04-2 분포 요약하기
import gdown
gdown.download('https://bit.ly/3pK7iuu', 'ns_book7.csv',quiet = False)
import matplotlib.pyplot as plt
산점도 그래프
- 데이터를 화면에 뿌리듯 그리는 그래프
- 두 변수 혹은 두 가지 특성값을 직교 좌표계에 점으로 나타내는 그래프
plt.scatter(ns_book7['번호'], ns_book7['대출건수']) #(x좌표, y좌표)
plt.show()
#투명도 조절하기
plt.scatter(ns_book7['도서권수'], ns_book7['대출건수'], alpha=0.1) #alpha 매개변수로 투명도 조절
plt.show()
히스토그램 그래프
- 수치형 특성의 값을 일정한 구간으로 나누어 구간 안에 포함된 데이터 개수를 막대 그래프로 그린 것
- 구간 안에 속한 데이터 개수를 도수라고 부름
- hist()함수, 기본적으로 데이터를 10개의 구간으로 나누지만 bin 매개변수를 통해 조절 가능
- 하나의 특성에 대한 분포를 확인하기 좋음
- 그래프의 x축, y축 스케일이 다르기때문에 비교하기는 쉽지 않음
plt.hist([0,3,5,6,7,7,9,13], bins=5)
plt.show()
⚠️한구간의 도수가 너무 큰 경우 다른 구간에는 도수 값이 표시되지 않는 현상이 발생함
--> 로그스케일 도입
plt.hist(ns_book7['대출건수']) #매개변수 log = True 로 지정해도 로그스케일 가능
plt.yscale('log')
plt.show()
마찬가지로 plt.xscale('log')를 사용하면 x스케일을 변화 시킬 수도 있다
상자 수염 그림
- 최솟값, 세 개의 사분위수, 최댓값 다섯 개의 숫자를 사용해 데이터를 요약하는 그래프를 그림
- 제 1분위수와 3분위수 사이의 거리를 IQR이라고 함
- 여러개의 특성을 시각적으로 비교하기 좋음
그리는 법

- 사분위수를 계산해 25%, 75% 지점을 밑면과 윗면으로 하는 직사각형을 그린다
- 중간값, 즉 50%에 해당하는 지점에 수평선을 긋는다
- 사각형의 밑면과 윗면에서 사각형의 높이의 1.5배만큼 떨어진 거리 안에서 가장 멀리 있는 샘플까지 수직선을 긋는다
- 이 수치선 밖에서 최솟값과 최댓값까지 데이터를 점으로 표시한다. 이 영역을 데이터 이상치라고 부름
plt.boxplot(ns_book7[['대출건수','도서권수']])
plt.yscale('log')
plt.show()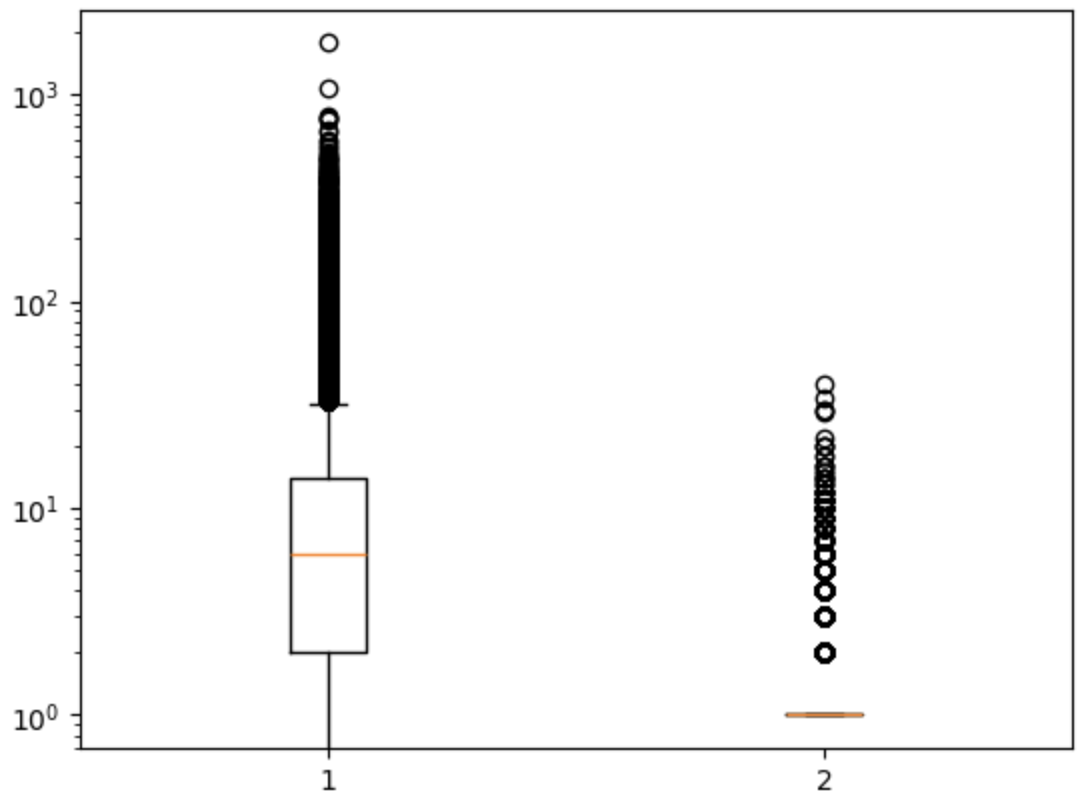
#수평으로 그리기
plt.boxplot(ns_book7[['대출건수','도서권수']], vert=False) #vert 매개변수를 통해 수평으로 그림
plt.xscale('log')
plt.show()
#수염 길이 조정하기
plt.boxplot(ns_book7[['대출건수','도서권수']], whis=10)#whis 함수를 통해 수염길이 조절 10배 범위 안까지 수염 그리기
plt.yscale('log')
plt.show()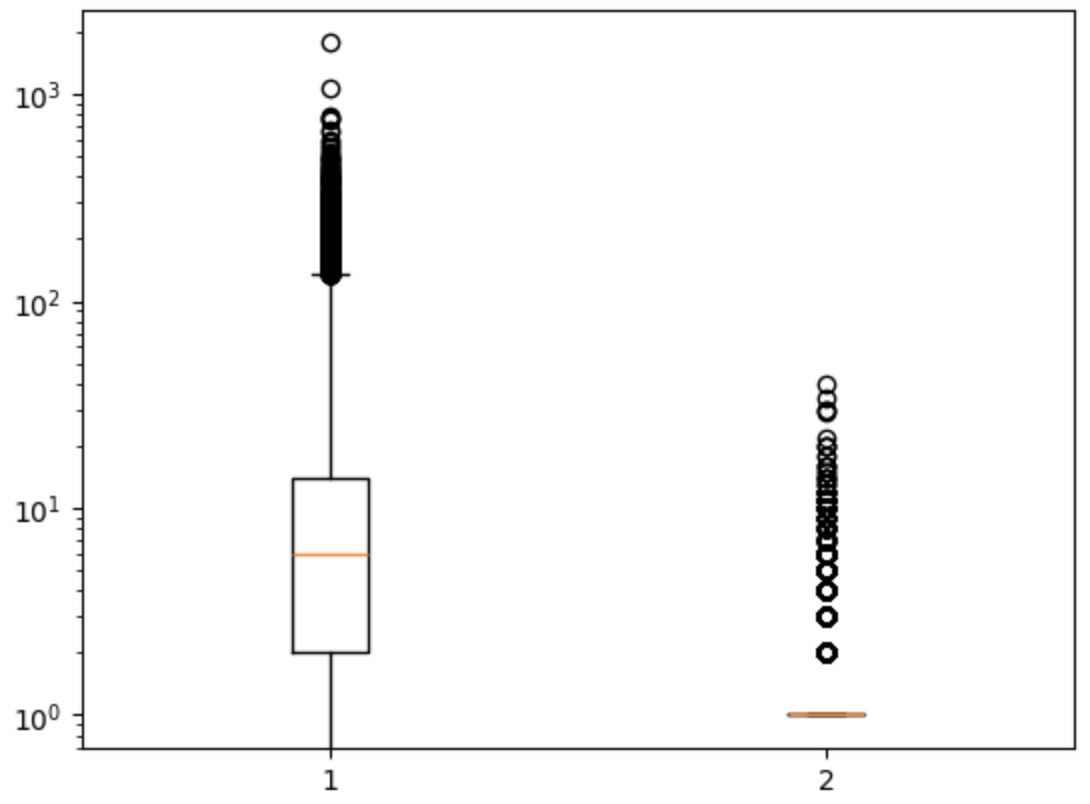
‼️판다스도 맷플롯립과 비슷한 메서드로 그래프그리기를 제공하지만 백엔드로 맷플롯립을 사용하기 때문에 대부분 결과가 같음
<추가 숙제>
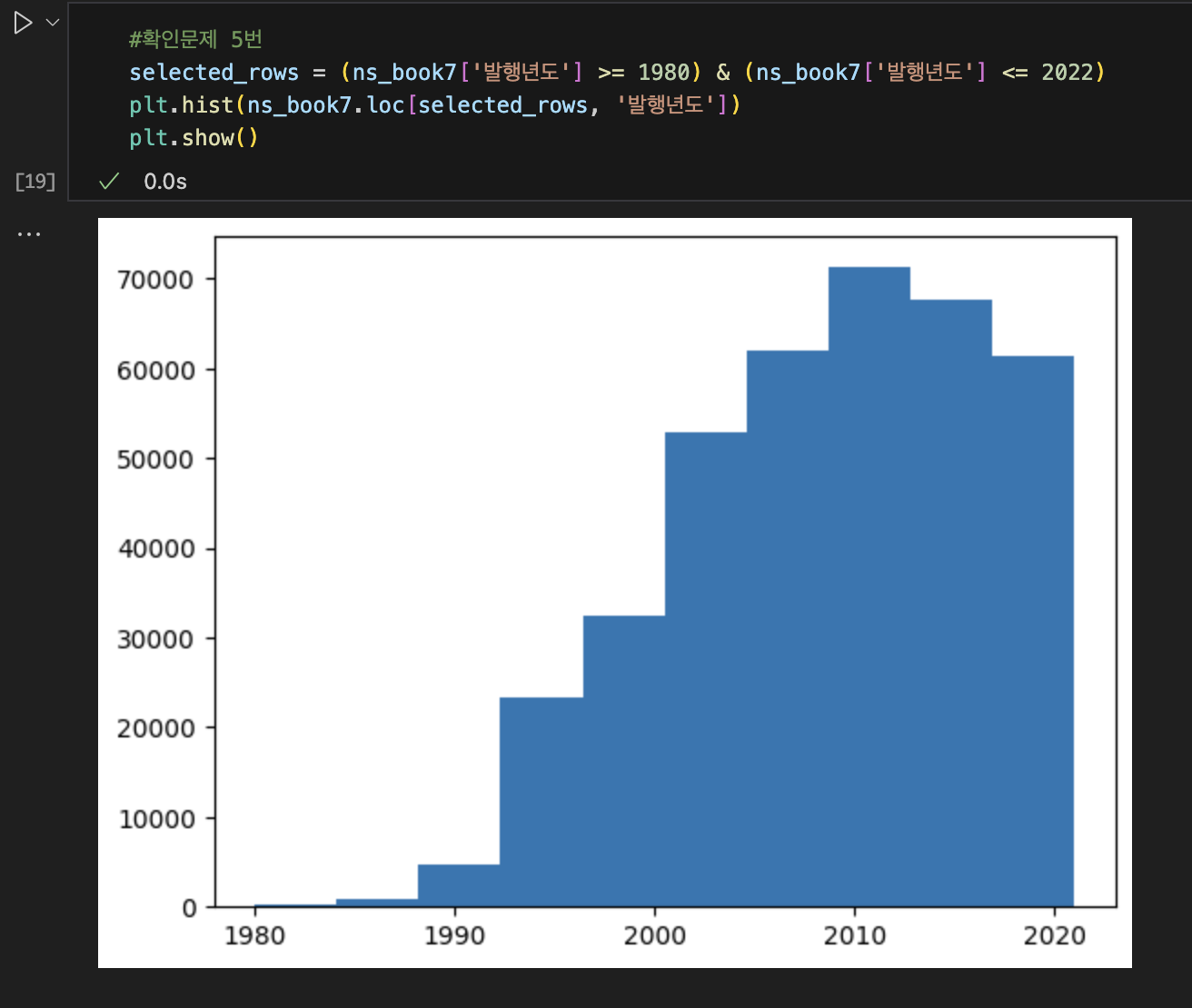
⚠️참고 사항
처음에 '&'이 아닌 and를 사용 했을 때 'ValueError: The truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all().' 라는 오류가 생겨 당황 했으나 구글링을 해보니 pandas를 이용할 때 '&'이 아닌 'and'를 사용하면 True 인지 False인지 제대로 판단을 못한다고 하더라 그래서 '&'으로 바꿔주고 해결!
내친김에 6번까지..
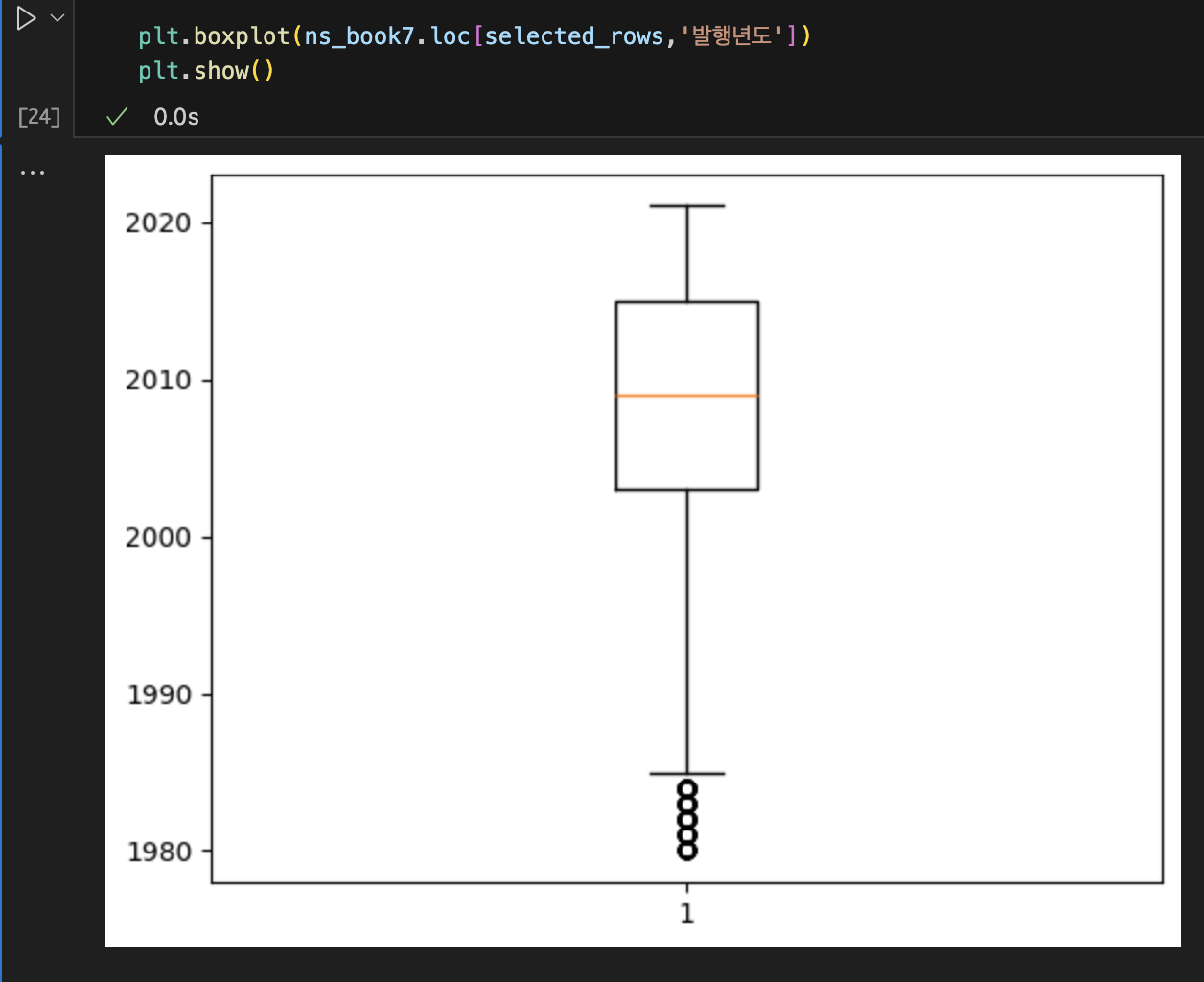
'컴붕이의 감자 탈출기 > 혼공분석' 카테고리의 다른 글
| [혼공분석]6주차_복잡한 데이터 표현하기 (0) | 2025.02.23 |
|---|---|
| [혼공분석] 5주차_데이터 시각화하기 (1) | 2025.02.06 |
| [혼공분석]3주차_데이터 정제하기 (1) | 2025.01.25 |
| [혼공분석]2주차_JSON, XML, 웹스크래핑 (2) | 2025.01.17 |
| [혼공분석]1주차_CSV파일의 이해 (0) | 2025.01.09 |