API?
- 두 프로그램이 서로 대화하기 위한 방법을 정의한 것
- API를 구현하는 방법은 다양하고 각기 장단점이 있음
- 웹기반 API는 주로 CSV, JSON, XML 형태로 데이터를 전달함

파이썬에서 JSON 데이터 다루기
JSON?
- JSON은 파이썬의 딕셔너리와 리스트를 중첩해놓은 것과 같은 '텍스트' 파일이다
- 웹 기반 API로 데이터를 전달할때는 파이썬 딕셔너리가 아니라 '텍스트'로 전달해야 한다
JSON 문자열 <--> Python 객체
d = {"name" : "혼공분석", "author" : "박해선", "year" : 2022}1. 파이썬 객체를 JSON문자열로 변환하기 : json.dump()함수
import json
d_str = json.dumps(d, ensure_ascii=False)
print(type(d_str)) //<class 'str'>2. JSON문자열을 파이썬 객체로 변환하기 : json.loads()함수
d2 = json.loads(d_str)
print(d2['name']) //혼공분석
JSON 배열
d4_str = """
[ //JSON배열
//JSON객체{"name" : "혼공분석" , "author" : "박해선", "year" : 2022},
{"name" : "혼공머신" , "author" : "박해선", "year" : 2020}
]
"""
d4 = json.loads(d4_str)
print(s=d4[0]['name']) // 혼공분석
JSON 문자열을 데이터 프레임으로 변환하기 : read_json()함수

파이썬에서 XML다루기
XML?
- eXtensible Markup Language의 약자

XML 문자열을 파이썬 객체로 변환하기: fromstring() 함수
x_str = """
<book>
<name>혼공분석</name>
<author>박해선</author>
<year>2022</year>
</book>
"""
import xml.etree.ElementTree as et
book = et.fromstring(x_str)‼️fromstring()함수가 반환하는 객체는 단순한 파이썬 객체가 아닌 모듈 아래에 정의된 Element 클래스의 객체임
자식 엘리먼트 확인하기: findtext() 매서드
name = book.findtext('name')
author = book.findtext('author')
year = book.findtext('year')
데이터프레임 행과 열 선택하기: loc 메서드
//books_df.loc[[행],[열]]
books_df.loc[[0,1],['bookname','authors']]이런 형태로 사용이 가능하다
리스트 대신 슬라이스 연산자를 사용하는 방법도 있다
books_df.loc[:, 'no':'isbn13']
웹 스크래핑 사용하기
웹 스크래핑 or 웹 크롤링
- 웹사이트의 페이지를 옮겨 가면서 데이터를 추출하는 작업
검색 결과 페이지 HTML 가져오기: reauests.get() 함수
import requests
url = 'url 주소'
r = requests.get(url)
print(r.text) //저 url에 사용된 HTML이 출력됨
HTML에서 데이터 추출하기: 뷰티플수프
https://potato2brain.tistory.com/8
[기본]Mac OS 사파리에서 개발자도구 사용법
1. 왼쪽 상단 'Safari'를 눌러 설정으로 들어간다 2. 고급을 눌러 맨 아래에 '웹 개발자를 위한 기능 보기' 를 활성화 시켜준다 3. 'option + command + u'를 누르면 개발자도구 창이 뜬다 4. 'shift + command +
potato2brain.tistory.com
from bs4 import BeautifulSuop
soup = BeautifulSoup(r.text, 'html.parser')
//첫번째 매개변수는 파싱할 HTML문서, 두번째는 파싱에 사용하는 파서
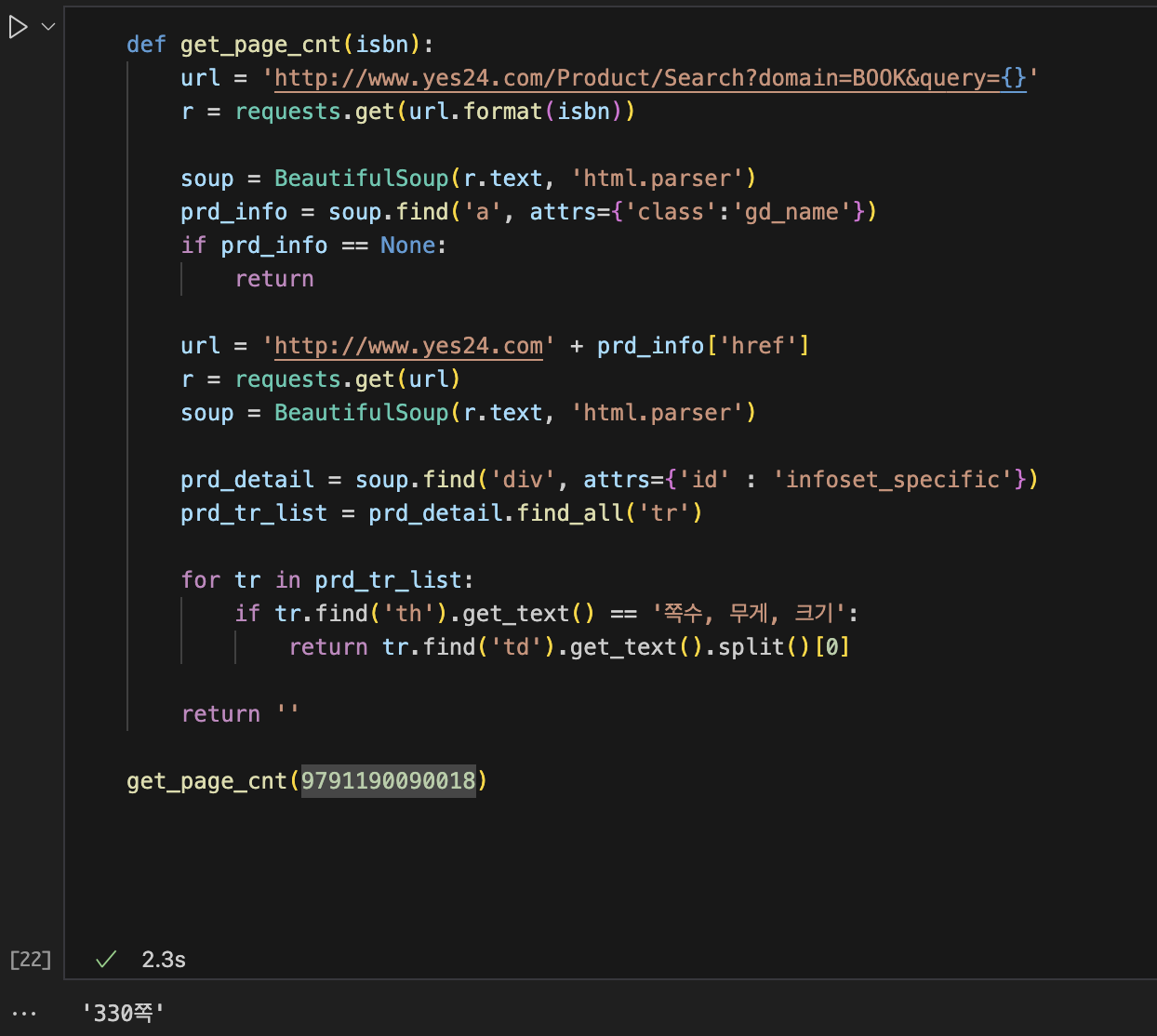
태그 위치 찾기: find 매서드
prd_link = soup.find('a', attrs = {'class':'gd_name'})'class'속성이 'gd_name'인 <a>태그를 찾으란 의미로 쓰인다
즉 첫번째 매개변수에는 찾을 태그 이름을 지정하고, attrs 매개변수에는 찾으려는 태그의 속성을 딕셔너리로 지정한다
❗️prd_link를 딕셔너리처럼 사용해 태그 안의 속성을 참조할 수 있다
특정 태그를 모두 찾아 리스트로 반환하기: find_all() 매서드
prd_tr_list = prd_detail.find_all('tr')
//<tr> 태그를 모두 찾아 리스트로 반환해줌
태그 안의 텍스트 가져오기: get_text() 매서드
for tr in prd_tr_list:
if tr.find('th').get_text() == '쪽수, 무게, 크기':
page_td = tr.find('td').get_text()
break먼저, <th>안의 텍스트 중 '쪽수, 무게, 크기'에 해당하는 태그를 찾는다
그 <th>태그 안에서 <td> 안의 텍스트를 page_td에 담아준다
데이터프레임 행 혹은 열에 함수 적용하기: apply() 메서드
- apply 메서드를 사용하면 데이터 프레임 행 또는 열에 함수를 일괄 적용이 가능함
- axis = 0 : 열에 적용, axis = 1 : 행에 적용
웹 스크래핑 주의할 점
- 웹사이트에서 스크래핑을 허락했나요?
- HTML 태그를 특정할 수 있나요?
- 페이지가 동적으로 생성되나요?
- 디자인이 자주 변경되나요?
필수 과제
P.150 1번 문제 풀기
정답: 5
df.loc[::2,'col1':'col2']를 하면 슬라이싱 할 때와 마찬가지로 두칸씩 뛰어 넘으면서 출력을 하게 됨 따라서 위에 있는 1,2,3,4번과는 다른 출력 결과가 나옴
선택 과제
'컴붕이의 감자 탈출기 > 혼공분석' 카테고리의 다른 글
| [혼공분석]6주차_복잡한 데이터 표현하기 (0) | 2025.02.23 |
|---|---|
| [혼공분석] 5주차_데이터 시각화하기 (2) | 2025.02.06 |
| [혼공분석]4주차_ 데이터 요약하기 (1) | 2025.01.27 |
| [혼공분석]3주차_데이터 정제하기 (1) | 2025.01.25 |
| [혼공분석]1주차_CSV파일의 이해 (1) | 2025.01.09 |



